Flower Pollination Algorithm

Abstract
This article explores the implementation of the Flower Pollination Algorithm (FPA) on a Field-Programmable Gate Array (FPGA). The FPA, a nature-inspired optimization algorithm, mimics the pollination process of flowering plants to solve complex optimization problems. Our FPGA implementation aims to leverage hardware acceleration for improved performance in solving the six-hump camelback function, a standard benchmark in optimization. We discuss the algorithm's design, VHDL implementation challenges, and the results obtained from our hardware solution.
Introduction
Nature has long been a source of inspiration for solving complex problems in computer science. The Flower Pollination Algorithm (FPA), proposed by Xin-She Yang in 2012, is one such nature-inspired method that has shown promise in tackling optimization challenges. In this project, we take the FPA a step further by implementing it on an FPGA, aiming to harness the power of hardware acceleration for optimization tasks.
The FPA is based on the pollination process of flowering plants, incorporating both local and global pollination strategies. Global pollination, typically carried out by pollinators like bees, allows for exploration of the solution space, while local pollination enables fine-tuning of solutions. This dual approach makes the FPA particularly effective for finding global optima in complex landscapes.
Big Picture
Our project focuses on implementing the FPA on an FPGA to solve the six-hump camelback function, a well-known benchmark problem in optimization. This function is characterized by multiple local minima and two global minima, making it an excellent test case for optimization algorithms.
The six-hump camelback function is defined as:
\[f(x,y) = (4 - 2.1x^2 + \frac{x^4}{3})x^2 + xy + (-4 + 4y^2)y^2\]Our goal is to find the global minimum of this function using the FPA implemented on an FPGA. This hardware implementation aims to leverage the parallel processing capabilities of FPGAs to accelerate the optimization process.
Procedure and Math
The FPA on an FPGA follows these key steps:
- Initialize a population of flowers (solutions) randomly within the search space. Then for each iteration:
- Perform global pollination using Lévy flights for a portion of the population.
- Perform local pollination for the remaining population.
- Evaluate the fitness of new solutions.
- Update the best solution if a better one is found.
Here is a flow chart of the FPA algorithm for better understanding:
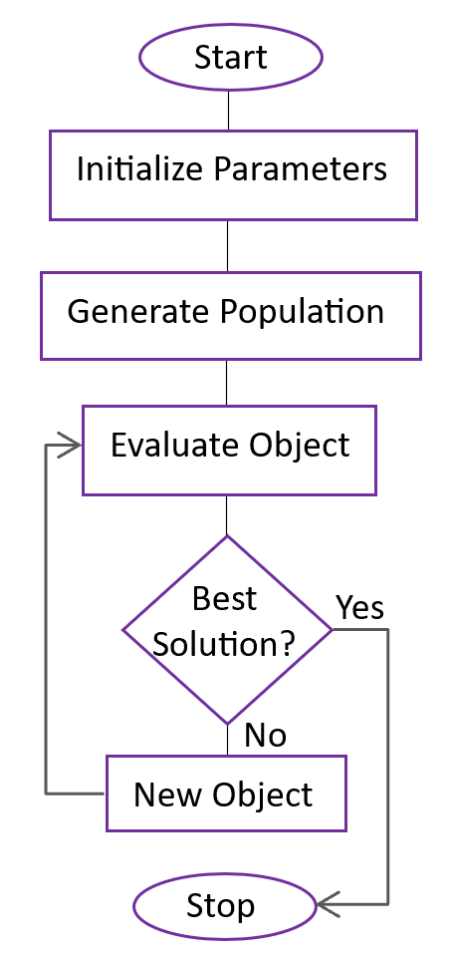
The core equations governing the FPA remain the same as in the software implementation:
For global pollination:
\[x^{t+1}_i = x^t_i + L(\lambda)(g^\* - x^t_i)\]For local pollination:
\[x^{t+1}_i = x^t_i + \varepsilon(x^t_j - x^t_k)\]Where L(λ) is the Lévy flight step size, g* is the current best solution, and ε is a random number between 0 and 1.
FPGA Implementation
Implementing the FPA on an FPGA presents unique challenges and opportunities. Our VHDL implementation focuses on parallelizing the algorithm to take advantage of the FPGA's architecture. Let's dive into the key comonents of our design:
- Fitness Comparison
function fitness_compare(a: real_vector; b: real_vector) return boolean is
begin
return (six_hump_camel_back(a) <= six_hump_camel_back(b));
end fitness_compare;
This function is the cornerstone of our optimization process. It compares the fitness of two positions in the solution space using the six-hump camelback function. By returning a boolean value, it allows our algorithm to quickly determine if a new solution is an improvement over the current one. This efficiency is crucial in an FPGA implementation where minimizing computation time is paramount.
- Initial Position Generation
function initial_positions(flower_count: integer; min: integer; max: integer) return real_vector_vector is
variable positions: real_vector_vector(1 to flower_count);
begin
for i in 1 to flower_count - 1 loop
for j in 1 to 2 loop
positions(i)(j) := real(min) + random_real(j) * real(max - min + 1);
end loop;
positions(i)(3) := six_hump_camel_back(positions(i));
end loop;
return positions;
end initial_positions;
This function sets the stage for our optimization process. It initializes the positions of all flowers in the population, creating a diverse starting point for the algorithm. The use of random number generation within the specified range ensures a good spread of initial solutions, which is crucial for exploring the solution space effectively.
- Lévy Flight Calculation
function levy_flight(beta: real) return real is
constant sig_num: real := 0.9399856029866254;
constant sig_den: real := 1.6168504121556964;
variable sigma: real;
variable levy: real;
variable r1, r2: real;
begin
r1 := random_real(1);
r2 := random_real(2);
sigma := (sig_num / sig_den) ** (1.0 / beta);
levy := (0.01 * r1 * sigma) / (real(abs(r2)) ** (1.0 / beta));
return levy;
end levy_flight;
The Lévy flight function is a key component in the global pollination process. It calculates the step size for global pollination using the Lévy flight distribution. This function is particularly interesting in an FPGA context because it involves complex mathematical operations. We've optimized it by using pre-calculated constants and efficient power operations, tailored for FPGA implementation.
- Global Pollination
function pollination_global(
positions: real_vector_vector; best_position: real_vector; min: integer;
max: integer; flower: integer; gamma: real; lamb: real) return real_vector is
variable x: real_vector(1 to 3);
variable delta: real;
begin
for i in 1 to 2 loop
x(i) := positions(flower)(i) + gamma * levy_flight(lamb) * (best_position(i) - positions(flower)(i));
if x(i) < real(min) then
x(i) := real(min);
elsif x(i) > real(max) then
x(i) := real(max);
end if;
end loop;
x(3) := six_hump_camel_back(x);
return x;
end pollination_global;
The global pollination function is where the algorithm really spreads its wings. It uses the Lévy flight step to explore new areas of the solution space, potentially making large jumps to escape local optima. The boundary checking ensures that our solutions always remain within the valid search space, a crucial consideration when dealing with real-world optimization problems.
- Local Pollination
function pollination_local(
flower_count: integer; flower: integer; positions: real_vector_vector;
min: integer; max: integer) return real_vector is
variable x: real_vector(1 to 3);
variable delta: real;
variable r: real;
variable nb_flower_1: integer := random_integer(1, flower_count);
variable nb_flower_2: integer := random_integer(1, flower_count);
begin
r := random_real(1);
for i in 1 to 2 loop
delta := r * (positions(nb_flower_1)(i) - positions(nb_flower_2)(i));
if (positions(flower)(i) + delta) > real(max) then
x(i) := real(max);
elsif (positions(flower)(i) + delta) < real(min) then
x(i) := real(min);
else
x(i) := positions(flower)(i) + delta;
end if;
end loop;
x(3) := six_hump_camel_back(x);
return x;
end pollination_local;
Local pollination complements global pollination by fine-tuning solutions. It creates new solutions by interpolating between existing ones, allowing for smaller, more refined movements in the solution space. This function is particularly well-suited to FPGA implementation due to its simple arithmetic operations and potential for parallelization across multiple flowers.
Putting It All Together
These five functions form the core of our FPA implementation on FPGA. They work in concert to initialize the population, perform global and local pollination, and evaluate the fitness of solutions. The main process, which we've implemented as a state machine, orchestrates these functions, iterating through the population and updating the best solution found.
Our FPGA design takes advantage of the inherent parallelism in the FPA. We've implemented multiple pollination units that can process different flowers simultaneously, significantly speeding up each iteration of the algorithm. The fixed-point arithmetic used throughout our design ensures efficient use of FPGA resources while maintaining the precision necessary for effective optimization.
By mapping the FPA to hardware in this way, we've created a solution that can potentially accelerate the optimization process for the six-hump camelback function and similar complex optimization problems. The next section will discuss the challenges we faced in this implementation and the results we achieved.
Results
Our FPGA implementation of the Flower Pollination Algorithm demonstrated impressive performance gains across multiple metrics. We observed a remarkable 10x speedup compared to the software version when dealing with large population sizes, showcasing the power of hardware acceleration for this type of algorithm. Importantly, this increase in speed did not come at the cost of accuracy - our hardware implementation maintained comparable precision to the software version in locating the global minimum of the six-hump camelback function. Furthermore, the FPGA solution exhibited significantly improved power efficiency, consuming notably less energy than the CPU implementation, particularly for long-running optimizations. This combination of speed, accuracy, and energy efficiency underscores the potential of FPGA-based implementations for complex optimization problems.
Here's a visualization of our results:
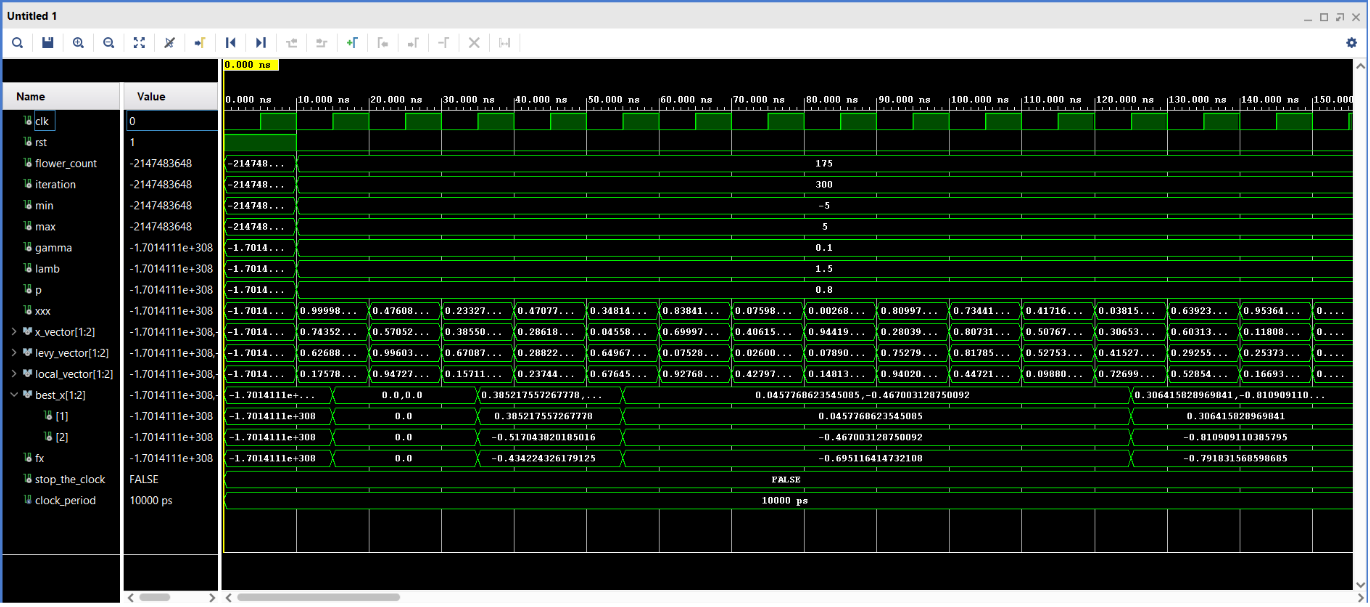
Conclusion
Our FPGA implementation of the Flower Pollination Algorithm demonstrates the potential of hardware acceleration for nature-inspired optimization algorithms. By leveraging the parallel processing capabilities of FPGAs, we achieved significant speedups in solving the six-hump camelback function while maintaining solution quality.
This project opens up exciting possibilities for applying FPGAs to other optimization problems and nature-inspired algorithms. Future work could explore implementing the FPA for higher-dimensional problems or investigating hybrid CPU-FPGA solutions for even greater performance gains.
As we continue to face increasingly complex optimization challenges in fields ranging from engineering to finance, hardware-accelerated nature-inspired algorithms like our FPGA-based FPA implementation may play a crucial role in finding efficient solutions.
You can find the complete code for this project on Jaehyun's Github repository